1.netty介绍.md
Netty 官方提供 3.x、4.x 的稳定版本,之前一直处于测试阶段的 5.x 版本已被作者放弃维护。此前,官方从未对外发布过任何 5.x 的稳定版本。我在工作中也会碰到一些业务方在开发新项目时直接使用 Netty 5.x 版本的情况,这是因为不少人信任 Netty 社区,并认为这样可以避免以后升级。可惜这一省事之举随着 5.x 版本废弃后全白费了。不过这也给我们带来了一个经验教训:尽可能不要在生产环境使用任何非稳定版本的组件。
2.netty配置优化.md
Netty服务端优化
在高并发场景下,服务端EventLoopGroup处理注册事件、任务处理1个处理能力是有限的,我尽可能使用最大,CUP:2*4,16线程,可配置最大16,这是测试,没有其它消耗
EventLoopGroup workerGroup = new NioEventLoopGroup(16);
高并发Handle处理请求业务使用业务线程池异步处理业务
ExecutorService businessThreadPool = Executors.newFixedThreadPool(16);
Netty4使用对象池,重用缓冲区
bootstrap.option(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT);
bootstrap.childOption(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT);
Linux 默认单进程打开的最大句柄数是1024,高并发场景需要修改最大句柄数
Netty客户端优化
自动调整下一次缓冲区建立时分配的空间大小,避免内存的浪费
bootstrap.option(ChannelOption.RCVBUF_ALLOCATOR, AdaptiveRecvByteBufAllocator.DEFAULT);
使用内存池
bootstrap.option(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT);
Netty客户端使用BlockingQueue对象池初始化,池的大小跟格CPU线程数进行配置,实现多Channel工作
Netty客户端实现心跳机制保持长链接,在空闲时每3秒做心跳
netty高性能调优
http://imwyy.xyz/2018/06/19/netty%E9%AB%98%E6%80%A7%E8%83%BD%E8%B0%83%E4%BC%98/
参考资料
3.netty学习笔记.md
为什么选择 Netty?
- I/O 模型、线程模型和事件处理机制;
- 易用性 API 接口;
- 对数据协议、序列化的支持
- 资源利用率高:内存池、零拷贝
1、I/O 多路复用

2、 异步 I/O

Reactor模型

Netty逻辑架构
Netty 的逻辑处理架构为典型网络分层架构设计,共分为网络通信层、事件调度层、服务编排层,每一层各司其职
- 网络通信层的核心组件包含BootStrap、ServerBootStrap、Channel三个组件。
- 事件调度层的核心组件包括 EventLoopGroup、EventLoop。
- 服务编排层的核心组件包括 ChannelPipeline、ChannelHandler、ChannelHandlerContext。
Reactor 的三种线程模型
- 单线程模型:EventLoopGroup 只包含一个 EventLoop,Boss 和 Worker 使用同一个EventLoopGroup;
- 多线程模型:EventLoopGroup 包含多个 EventLoop,Boss 和 Worker 使用同一个EventLoopGroup;
- 主从多线程模型:EventLoopGroup 包含多个 EventLoop,Boss 是主 Reactor,Worker 是从 Reactor,它们分别使用不同的 EventLoopGroup,主 Reactor 负责新的网络连接 Channel 创建,然后把 Channel 注册到从 Reactor。
Netty线程模型
NioEventLoop 无锁串行化的设计不仅使系统吞吐量达到最大化,而且降低了用户开发业务逻辑的难度,不需要花太多精力关心线程安全问题。虽然单线程执行避免了线程切换,但是它的缺陷就是不能执行时间过长的 I/O 操作,一旦某个 I/O 事件发生阻塞,那么后续的所有 I/O 事件都无法执行,甚至造成事件积压。在使用 Netty 进行程序开发时,我们一定要对 ChannelHandler 的实现逻辑有充分的风险意识。
在 JDK 中, Epoll 的实现是存在漏洞的,即使 Selector 轮询的事件列表为空,NIO 线程一样可以被唤醒,导致 CPU 100% 占用。这就是臭名昭著的 JDK epoll 空轮询的 Bug。
Netty EventLoop 的功能用处做一个简单的归纳总结。
- MainReactor 线程:处理客户端请求接入。
- SubReactor 线程:数据读取、I/O 事件的分发与执行。
- 任务处理线程:用于执行普通任务或者定时任务,如空闲连接检测、心跳上报等。
Netty组件
EventLoop 可以说是 Netty 的调度中心,负责监听多种事件类型:I/O 事件、信号事件、定时事件
ChannelPipeline 双向链表的构造,ChannelPipeline 的双向链表分别维护了 HeadContext 和 TailContext 的头尾节点。我们自定义的 ChannelHandler 会插入到 Head 和 Tail 之间,这两个节点在 Netty 中已经默认实现了
ChannelPipeline 事件传播的实现采用了经典的责任链模式,调用链路环环相扣
在 Netty 应用开发的过程中,良好的异常处理机制会让排查问题的过程事半功倍。所以推荐用户对异常进行统一拦截,然后根据实际业务场景实现更加完善的异常处理机制。通过异常传播机制的学习,我们应该可以想到最好的方法是在 ChannelPipeline 自定义处理器的末端添加统一的异常处理器,此时 ChannelPipeline 的内部结构如下图所示。

异常事件的处理顺序与 ChannelHandler 的添加顺序相同,会依次向后传播,与 Inbound 事件和 Outbound 事件无关。
Netty网络处理
MTU 最大传输单元和 MSS 最大分段大小
MTU(Maxitum Transmission Unit) 是链路层一次最大传输数据的大小。MTU 一般来说大小为 1500 byte。MSS(Maximum Segement Size) 是指 TCP 最大报文段长度,它是传输层一次发送最大数据的大小。如下图所示,MTU 和 MSS 一般的计算关系为:MSS = MTU - IP 首部 - TCP首部,如果 MSS + TCP 首部 + IP 首部 > MTU,那么数据包将会被拆分为多个发送。这就是拆包现象。

滑动窗口
滑动窗口是 TCP 传输层用于流量控制的一种有效措施,也被称为通告窗口。滑动窗口是数据接收方设置的窗口大小,随后接收方会把窗口大小告诉发送方,以此限制发送方每次发送数据的大小,从而达到流量控制的目的。
Nagle 算法
Nagle 算法于 1984 年被福特航空和通信公司定义为 TCP/IP 拥塞控制方法。它主要用于解决频繁发送小数据包而带来的网络拥塞问题
Nagle 算法可以理解为批量发送,也是我们平时编程中经常用到的优化思路,它是在数据未得到确认之前先写入缓冲区,等待数据确认或者缓冲区积攒到一定大小再把数据包发送出去。
你可以通过 Linux 提供的 TCP_NODELAY 参数禁用 Nagle 算法。Netty 中为了使数据传输延迟最小化,就默认禁用了 Nagle 算法,这一点与 Linux 操作系统的默认行为是相反的。
解包算法
- 消息长度固定
- 特定分隔符(如redis)
- 消息长度 + 消息内容( Dubbo、RocketMQ )
Netty通信协议设计
通信协议设计
自定义协议主要有以下优点
- 极致性能:通用的通信协议考虑了很多兼容性的因素,必然在性能方面有所损失。
- 扩展性:自定义的协议相比通用协议更好扩展,可以更好地满足自己的业务需求。
- 通用协议是公开的,很多漏洞已经很多被黑客攻破。自定义协议更加安全,因为黑客需要先破解你的协议内容。
完备的网络协议需要具备哪些基本要素
- 魔数
- 协议版本号
- 序列化算法
- 报文类型
- 长度域字段
- 请求数据
- 状态
- 保留字段
较为通用的协议示例:
+---------------------------------------------------------------+
| 魔数 2byte | 协议版本号 1byte | 序列化算法 1byte | 报文类型 1byte |
+---------------------------------------------------------------+
| 状态 1byte | 保留字段 4byte | 数据长度 4byte |
+---------------------------------------------------------------+
| 数据内容 (长度不定) |
+---------------------------------------------------------------+
编解码器可以分为一次解码器和二次解码器,一次解码器用于解决 TCP 拆包/粘包问题,按协议解析后得到的字节数据。如果你需要对解析后的字节数据做对象模型的转换,这时候便需要用到二次解码器,同理编码器的过程是反过来的。
通信协议实战
在上述通信协议设计的小节内容中,我们提到了协议的基本要素并给出了一个较为通用的协议示例。下面我们通过 Netty 的编辑码框架实现该协议的解码器,加深我们对 Netty 编解码框架的理解。
在实现协议编码器之前,我们首先需要清楚一个问题:如何判断 ByteBuf 是否存在完整的报文?最常用的做法就是通过读取消息长度 dataLength 进行判断。如果 ByteBuf 的可读数据长度小于 dataLength,说明 ByteBuf 还不够获取一个完整的报文。在该协议前面的消息头部分包含了魔数、协议版本号、数据长度等固定字段,共 14 个字节。固定字段长度和数据长度可以作为我们判断消息完整性的依据,具体编码器实现逻辑示例如下:
/*
+---------------------------------------------------------------+
| 魔数 2byte | 协议版本号 1byte | 序列化算法 1byte | 报文类型 1byte |
+---------------------------------------------------------------+
| 状态 1byte | 保留字段 4byte | 数据长度 4byte |
+---------------------------------------------------------------+
| 数据内容 (长度不定) |
+---------------------------------------------------------------+
*/
@Override
public final void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) {
// 判断 ByteBuf 可读取字节
if (in.readableBytes() < 14) {
return;
}
in.markReaderIndex(); // 标记 ByteBuf 读指针位置
in.skipBytes(2); // 跳过魔数
in.skipBytes(1); // 跳过协议版本号
byte serializeType = in.readByte();
in.skipBytes(1); // 跳过报文类型
in.skipBytes(1); // 跳过状态字段
in.skipBytes(4); // 跳过保留字段
int dataLength = in.readInt();
if (in.readableBytes() < dataLength) {
in.resetReaderIndex(); // 重置 ByteBuf 读指针位置
return;
}
byte[] data = new byte[dataLength];
in.readBytes(data);
SerializeService serializeService = getSerializeServiceByType(serializeType);
Object obj = serializeService.deserialize(data);
if (obj != null) {
out.add(obj);
}
}
Netty常用编码解码器
ByteToMessageDecoder提供的一些常见的实现类:
FixedLengthFrameDecoder:定长协议解码器,我们可以指定固定的字节数算一个完整的报文
LineBasedFrameDecoder: 行分隔符解码器,遇到\n或者\r\n,则认为是一个完整的报文
DelimiterBasedFrameDecoder: 分隔符解码器,与LineBasedFrameDecoder类似,只不过分隔符可以自己指定
LengthFieldBasedFrameDecoder:长度编码解码器,将报文划分为报文头/报文体,根据报文头中的Length字段确定报文体的长度,因此报文提的长度是可变的
JsonObjectDecoder:json格式解码器,当检测到匹配数量的"{" 、”}”或”[””]”时,则认为是一个完整的json对象或者json数组。
MessageToMessageEncoder提供的常见子类包括:
LineEncoder:按行编码,给定一个CharSequence(如String),在其之后添加换行符\n或者\r\n,并封装到ByteBuf进行输出,与LineBasedFrameDecoder相对应。
Base64Encoder:给定一个ByteBuf,得到对其包含的二进制数据进行Base64编码后的新的ByteBuf进行输出,与Base64Decoder相对应。
LengthFieldPrepender:给定一个ByteBuf,为其添加报文头Length字段,得到一个新的ByteBuf进行输出。Length字段表示报文长度,与LengthFieldBasedFrameDecoder相对应。
StringEncoder:给定一个CharSequence(如:StringBuilder、StringBuffer、String等),将其转换成ByteBuf进行输出,与StringDecoder对应。
这些MessageToMessageEncoder实现类最终输出的都是ByteBuf,因为最终在网络上传输的都要是二进制数据。
##writeAndFlush流程
writeAndFlush 属于出站操作,它是从 Pipeline 的 Tail 节点开始进行事件传播,一直向前传播到 Head 节点。不管在 write 还是 flush 过程,Head 节点都中扮演着重要的角色。
write 方法并没有将数据写入 Socket 缓冲区,只是将数据写入到 ChannelOutboundBuffer 缓存中,ChannelOutboundBuffer 缓存内部是由单向链表实现的。
flush 方法才最终将数据写入到 Socket 缓冲区。
- channel写的话,数据会从Tail开始往Head传播(当然是在outbount上)
- 用ChannelHandlerContext的话,会从当前节点往Head传播(不会通过Tail了)
堆外内存
堆外内存和堆内内存各有利弊,这里我针对其中重要的几点进行说明。
-
堆内内存由 JVM GC 自动回收内存,降低了 Java 用户的使用心智,但是 GC 是需要时间开销成本的,堆外内存由于不受 JVM 管理,所以在一定程度上可以降低 GC 对应用运行时带来的影响。
-
堆外内存需要手动释放,这一点跟 C/C++ 很像,稍有不慎就会造成应用程序内存泄漏,当出现内存泄漏问题时排查起来会相对困难。
-
当进行网络 I/O 操作、文件读写时,堆内内存都需要转换为堆外内存,然后再与底层设备进行交互,这一点在介绍 writeAndFlush 的工作原理中也有提到,所以直接使用堆外内存可以减少一次内存拷贝。
-
堆外内存可以实现进程之间、JVM 多实例之间的数据共享。
Java 中堆外内存的分配方式有两种:
ByteBuffer#allocateDirect > 不需要手动释放
Unsafe#allocateMemory > 需要手动释放
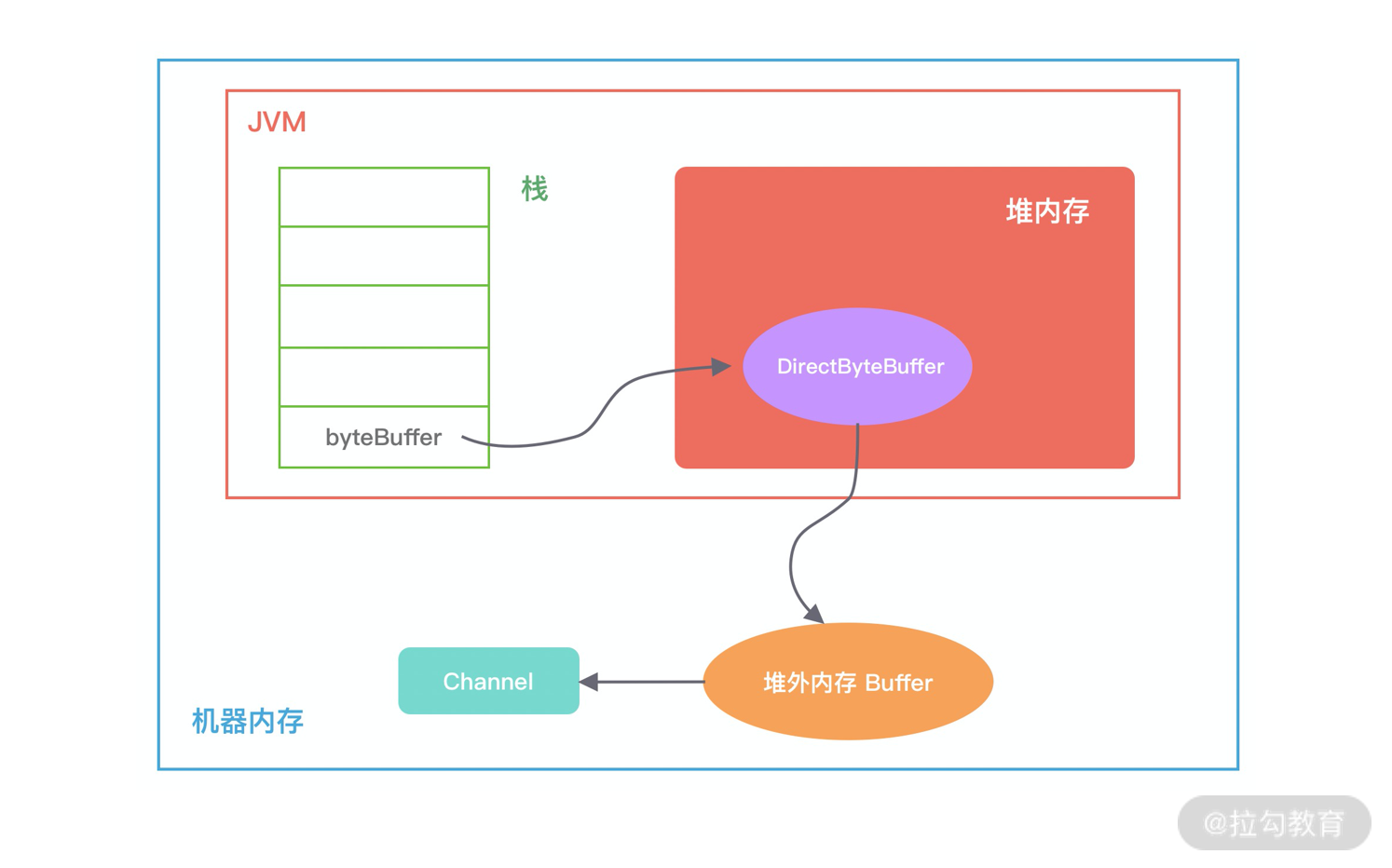
DirectByteBuffer 如何避免物理内存被耗尽呢?
因为 JVM 并不知道堆外内存是不是已经不足了,所以我们最好通过 JVM 参数 -XX:MaxDirectMemorySize 指定堆外内存的上限大小,当堆外内存的大小超过该阈值时,就会触发一次 Full GC 进行清理回收,如果在 Full GC 之后还是无法满足堆外内存的分配,那么程序将会抛出 OOM 异常。
Cleaner 对象在初始化时会加入 Cleaner 链表中。DirectByteBuffer 对象包含堆外内存的地址、大小以及 Cleaner 对象的引用,ReferenceQueue 用于保存需要回收的 Cleaner 对象。
###数据容器 ByteBuf
ByteBuf 有多种实现类,每种都有不同的特性,下图是 ByteBuf 的家族图谱,可以划分为三个不同的维度:Heap/Direct、Pooled/Unpooled和Unsafe/非 Unsafe。
ByteBuf API 使用时的注意点:
-
write 系列方法会改变 writerIndex 位置,当 writerIndex 等于 capacity 的时候,Buffer 置为不可写状态;
-
向不可写 Buffer 写入数据时,Buffer 会尝试扩容,但是扩容后 capacity 最大不能超过 maxCapacity,如果写入的数据超过 maxCapacity,程序会直接抛出异常;
-
read 系列方法会改变 readerIndex 位置,get/set 系列方法不会改变 readerIndex/writerIndex 位置。
本节课我们介绍了 Netty 强大的数据容器 ByteBuf,它不仅解决了 JDK NIO 中 ByteBuffer 的缺陷,而且提供了易用性更强的接口。很多开发者已经使用 ByteBuf 代替 ByteBuffer,即便他没有在写一个网络应用,也会单独使用 ByteBuf。ByteBuf 作为 Netty 中最基础的数据结构,你必须熟练掌握它,这是你精通 Netty 的必经之路,接下来的课程我们会围绕 ByteBuf 介绍关于 Netty 内存管理的相关设计。
常用内存分配器算法
在学习 jemalloc 的实现原理之前,我们先了解下最常用的内存分配器算法:动态内存分配、伙伴算法和Slab 算法,这将对于我们理解 jemalloc 大有裨益。
Linux 内核使用的就是 Slab 算法,因为内核需要频繁地分配小内存,所以 Slab 算法提供了一种高速缓存机制,使用缓存存储内核对象,当内核需要分配内存时,基本上可以通过缓存中获取。此外 Slab 算法还可以支持通用对象的初始化操作,避免对象重复初始化的开销。下图是 Slab 算法的结构图,Slab 算法实现起来非常复杂,本文只做一个简单的了解。

在 Slab 算法中维护着大小不同的 Slab 集合,在最顶层是 cache_chain,cache_chain 中维护着一组 kmem_cache 引用,kmem_cache 负责管理一块固定大小的对象池。通常会提前分配一块内存,然后将这块内存划分为大小相同的 slot,不会对内存块再进行合并,同时使用位图 bitmap 记录每个 slot 的使用情况。
kmem_cache 中包含三个 Slab 链表:完全分配使用 slab_full、部分分配使用 slab_partial和完全空闲 slabs_empty,这三个链表负责内存的分配和释放。每个链表中维护的 Slab 都是一个或多个连续 Page,每个 Slab 被分配多个对象进行存储。Slab 算法是基于对象进行内存管理的,它把相同类型的对象分为一类。当分配内存时,从 Slab 链表中划分相应的内存单元;当释放内存时,Slab 算法并不会丢弃已经分配的对象,而是将它保存在缓存中,当下次再为对象分配内存时,直接会使用最近释放的内存块。
单个 Slab 可以在不同的链表之间移动,例如当一个 Slab 被分配完,就会从 slab_partial 移动到 slabs_full,当一个 Slab 中有对象被释放后,就会从 slab_full 再次回到 slab_partial,所有对象都被释放完的话,就会从 slab_partial 移动到 slab_empty。
Netty 内存池架构设计
Netty 中的内存池可以看作一个 Java 版本的 jemalloc 实现,并结合 JVM 的诸多特性做了部分优化。
Netty 在每个区域内又定义了更细粒度的内存分配单位,分别为 Chunk、Page、Subpage,我们将逐一对其进行介绍。
Page 是 Chunk 用于管理内存的单位,Netty 中的 Page 的大小为 8K,不要与 Linux 中的内存页 Page 相混淆了。假如我们需要分配 64K 的内存,需要在 Chunk 中选取 4 个 Page 进行分配。是不是需要8个page进行分配
Netty 中负责线程分配的组件有两个:PoolArena和PoolThreadCache。PoolArena 是多个线程共享的,每个线程会固定绑定一个 PoolArena,PoolThreadCache 是每个线程私有的缓存空间。

Netty 内存池的设计思想做一个知识点总结:
-
分四种内存规格管理内存,分别为 Tiny、Samll、Normal、Huge,PoolChunk 负责管理 8K 以上的内存分配,PoolSubpage 用于管理 8K 以下的内存分配。当申请内存大于 16M 时,不会经过内存池,直接分配。
-
设计了本地线程缓存机制 PoolThreadCache,用于提升内存分配时的并发性能。用于申请 Tiny、Samll、Normal 三种类型的内存时,会优先尝试从 PoolThreadCache 中分配。
-
PoolChunk 使用伙伴算法管理 Page,以二叉树的数据结构实现,是整个内存池分配的核心所在。
-
每调用 PoolThreadCache 的 allocate() 方法到一定次数,会触发检查 PoolThreadCache 中缓存的使用频率,使用频率较低的内存块会被释放。
-
线程退出时,Netty 会回收该线程对应的所有内存。
Recycler 的设计理念
对象池与内存池的都是为了提高 Netty 的并发处理能力,我们知道 Java 中频繁地创建和销毁对象的开销是很大的,所以很多人会将一些通用对象缓存起来,当需要某个对象时,优先从对象池中获取对象实例。通过重用对象,不仅避免频繁地创建和销毁所带来的性能损耗,而且对 JVM GC 是友好的,这就是对象池的作用。
-
对象池有两个重要的组成部分:Stack 和 WeakOrderQueue。
-
从 Recycler 获取对象时,优先从 Stack 中查找,如果 Stack 没有可用对象,会尝试从 WeakOrderQueue 迁移部分对象到 Stack 中。
-
Recycler 回收对象时,分为同线程对象回收和异线程对象回收两种情况,同线程回收直接向 Stack 中添加对象,异线程回收向 WeakOrderQueue 中的 Link 添加对象。
-
对象回收都会控制回收速率,每 8 个对象会回收一个,其他的全部丢弃。
Netty 零拷贝技术
传统 Linux 中的零拷贝技术
在介绍 Netty 零拷贝特性之前,我们有必要学习下传统 Linux 中零拷贝的工作原理。所谓零拷贝,就是在数据操作时,不需要将数据从一个内存位置拷贝到另外一个内存位置,这样可以减少一次内存拷贝的损耗,从而节省了 CPU 时钟周期和内存带宽。
我们模拟一个场景,从文件中读取数据,然后将数据传输到网络上,那么传统的数据拷贝过程会分为哪几个阶段呢?具体如下图所示。

从上图中可以看出,从数据读取到发送一共经历了四次数据拷贝,具体流程如下:
-
当用户进程发起 read() 调用后,上下文从用户态切换至内核态。DMA 引擎从文件中读取数据,并存储到内核态缓冲区,这里是第一次数据拷贝。
-
请求的数据从内核态缓冲区拷贝到用户态缓冲区,然后返回给用户进程。第二次数据拷贝的过程同时,会导致上下文从内核态再次切换到用户态。
-
用户进程调用 send() 方法期望将数据发送到网络中,此时会触发第三次线程切换,用户态会再次切换到内核态,请求的数据从用户态缓冲区被拷贝到 Socket 缓冲区。
-
最终 send() 系统调用结束返回给用户进程,发生了第四次上下文切换。第四次拷贝会异步执行,从 Socket 缓冲区拷贝到协议引擎中。
在 Linux 中系统调用 sendfile() 可以实现将数据从一个文件描述符传输到另一个文件描述符,从而实现了零拷贝技术。在 Java 中也使用了零拷贝技术,它就是 NIO FileChannel 类中的 transferTo() 方法,transferTo() 底层就依赖了操作系统零拷贝的机制,它可以将数据从 FileChannel 直接传输到另外一个 Channel。
public abstract long transferTo(long position, long count, WritableByteChannel target) throws IOException;
public void testTransferTo() throws IOException {
RandomAccessFile fromFile = new RandomAccessFile("from.data", "rw");
FileChannel fromChannel = fromFile.getChannel();
RandomAccessFile toFile = new RandomAccessFile("to.data", "rw");
FileChannel toChannel = toFile.getChannel();
long position = 0;
long count = fromChannel.size();
fromChannel.transferTo(position, count, toChannel);
}

比较大的一个变化是,DMA 引擎从文件中读取数据拷贝到内核态缓冲区之后,由操作系统直接拷贝到 Socket 缓冲区,不再拷贝到用户态缓冲区,所以数据拷贝的次数从之前的 4 次减少到 3 次。
但是上述的优化离达到零拷贝的要求还是有差距的,能否继续减少内核中的数据拷贝次数呢?在 Linux 2.4 版本之后,开发者对 Socket Buffer 追加一些 Descriptor 信息来进一步减少内核数据的复制。如下图所示,DMA 引擎读取文件内容并拷贝到内核缓冲区,然后并没有再拷贝到 Socket 缓冲区,只是将数据的长度以及位置信息被追加到 Socket 缓冲区,然后 DMA 引擎根据这些描述信息,直接从内核缓冲区读取数据并传输到协议引擎中,从而消除最后一次 CPU 拷贝。

通过上述 Linux 零拷贝技术的介绍,你也许还会存在疑问,最终使用零拷贝之后,不是还存在着数据拷贝操作吗?其实从 Linux 操作系统的角度来说,零拷贝就是为了避免用户态和内存态之间的数据拷贝。无论是传统的数据拷贝还是使用零拷贝技术,其中有 2 次 DMA 的数据拷贝必不可少,只是这 2 次 DMA 拷贝都是依赖硬件来完成,不需要 CPU 参与。所以,在这里我们讨论的零拷贝是个广义的概念,只要能够减少不必要的 CPU 拷贝,都可以被称为零拷贝。
Netty 中的零拷贝技术除了操作系统级别的功能封装,更多的是面向用户态的数据操作优化,主要体现在以下 5 个方面:
- 堆外内存,避免 JVM 堆内存到堆外内存的数据拷贝。
- CompositeByteBuf 类,可以组合多个 Buffer 对象合并成一个逻辑上的对象,避免通过传统内存拷贝的方式将几个 Buffer 合并成一个大的 Buffer。
- 通过 Unpooled.wrappedBuffer 可以将 byte 数组包装成 ByteBuf 对象,包装过程中不会产生内存拷贝。
- ByteBuf.slice 操作与 Unpooled.wrappedBuffer 相反,slice 操作可以将一个 ByteBuf 对象切分成多个 ByteBuf 对象,切分过程中不会产生内存拷贝,底层共享一个 byte 数组的存储空间。
- Netty 使用 FileRegion 实现文件传输,FileRegion 底层封装了 FileChannel#transferTo() 方法,可以将文件缓冲区的数据直接传输到目标 Channel,避免内核缓冲区和用户态缓冲区之间的数据拷贝,这属于操作系统级别的零拷贝。
Netty源码
在课程开始之前,我想分享一下关于源码学习的几点经验和建议。第一,很多同学在开始学习源码时面临的第一个问题就是不知道从何下手,这个时候一定不能对着源码毫无意义地四处翻看。建议你可以通过 Hello World 或者 TestCase 作为源码学习的入口,然后再通过 Debug 断点的方式调试并跑通源码。第二,阅读源码一定要有全局观。首先要把握源码的主流程,避免刚开始陷入代码细节的死胡同。第三,源码一定要反复阅读,让自己每一次读都有不同的收获。我们可以通过画图、注释的方式帮助自己更容易理解源码的核心流程,方便后续的复习和回顾。
Netty 服务端启动的全流程

Reactor 线程执行的主流程
通过 NioEventLoop 的核心入口 run() 方法回顾 Netty Reactor 线程模型执行的主流程,并以此为基础继续深入研究 NioEventLoop 的逻辑细节。
protected void run() {
for (;;) {
try {
try {
switch (selectStrategy.calculateStrategy(selectNowSupplier, hasTasks())) {
case SelectStrategy.CONTINUE:
continue;
case SelectStrategy.BUSY_WAIT:
case SelectStrategy.SELECT:
select(wakenUp.getAndSet(false)); // 轮询 I/O 事件
if (wakenUp.get()) {
selector.wakeup();
}
default:
}
} catch (IOException e) {
rebuildSelector0();
handleLoopException(e);
continue;
}
cancelledKeys = 0;
needsToSelectAgain = false;
final int ioRatio = this.ioRatio;
if (ioRatio == 100) {
try {
processSelectedKeys(); // 处理 I/O 事件
} finally {
runAllTasks(); // 处理所有任务
}
} else {
final long ioStartTime = System.nanoTime();
try {
processSelectedKeys(); // 处理 I/O 事件
} finally {
final long ioTime = System.nanoTime() - ioStartTime;
runAllTasks(ioTime * (100 - ioRatio) / ioRatio); // 处理完 I/O 事件,再处理异步任务队列
}
}
} catch (Throwable t) {
handleLoopException(t);
}
try {
if (isShuttingDown()) {
closeAll();
if (confirmShutdown()) {
return;
}
}
} catch (Throwable t) {
handleLoopException(t);
}
}
}
-
轮询 I/O 事件(select):轮询 Selector 选择器中已经注册的所有 Channel 的 I/O 事件。
-
处理 I/O 事件(processSelectedKeys):处理已经准备就绪的 I/O 事件。
-
处理异步任务队列(runAllTasks):Reactor 线程还有一个非常重要的职责,就是处理任务队列中的非 I/O 任务。Netty 提供了 ioRatio 参数用于调整 I/O 事件处理和任务处理的时间比例。
NioEventLoop 内部有两个非常重要的异步任务队列,分别为普通任务队列和定时任务队列。NioEventLoop 提供了 execute() 和 schedule() 方法用于向不同的队列中添加任务,execute() 用于添加普通任务,schedule() 方法用于添加定时任务。
Netty 巧妙地借助普通任务的 Mpsc Queue 解决多线程并发操作时的线程安全问题。Netty 执行任务之前会将满足条件的定时任务合并到普通任务队列,由普通任务队列统一负责执行,并且每执行 64 个任务的时候就会检查一下是否超时。
一个网络请求在 Netty 中的旅程
Netty 在服务端启动时会为创建 NioServerSocketChannel,
当客户端新连接接入时又会创建 NioSocketChannel,
不管是服务端还是客户端 Channel,在创建时都会初始化自己的 ChannelPipeline。
如果把 Netty 比作成一个生产车间,那么 Reactor 线程无疑是车间的中央管控系统,ChannelPipeline 可以看作是车间的流水线,将原材料按顺序进行一步步加工,然后形成一个完整的产品

知识点总结:
-
ChannelPipeline 是双向链表结构,包含 ChannelInboundHandler 和 ChannelOutboundHandler 两种处理器。
-
Inbound 事件和 Outbound 事件的传播方向相反,Inbound 事件的传播方向为 Head -> Tail,而 Outbound 事件传播方向是 Tail -> Head。
-
异常事件的处理顺序与 ChannelHandler 的添加顺序相同,会依次向后传播,与 Inbound 事件和 Outbound 事件无关。
再整体回顾下 ChannelPipeline 中事件传播的实现原理:
-
Inbound 事件传播从 HeadContext 节点开始,Outbound 事件传播从 TailContext 节点开始。
-
AbstractChannelHandlerContext 抽象类中实现了一系列 fire 和 invoke 方法,如果想让事件想下传播,只需要调用 fire 系列的方法即可。fire 和 invoke 的系列方法结合 findContextInbound() 和 findContextOutbound() 可以控制 Inbound 和 Outbound 事件的传播方向,整个过程是一个递归调用。
Netty 的 FastThreadLocal
ThreadLocal 的实现原理
既然多线程访问 ThreadLocal 变量时都会有自己独立的实例副本,那么很容易想到的方案就是在 ThreadLocal 中维护一个 Map,记录线程与实例之间的映射关系。当新增线程和销毁线程时都需要更新 Map 中的映射关系,因为会存在多线程并发修改,所以需要保证 Map 是线程安全的。那么 JDK 的 ThreadLocal 是这么实现的吗?答案是 NO。因为在高并发的场景并发修改 Map 需要加锁,势必会降低性能。JDK 为了避免加锁,采用了相反的设计思路。以 Thread 入手,在 Thread 中维护一个 Map,记录 ThreadLocal 与实例之间的映射关系,这样在同一个线程内,Map 就不需要加锁了。
###ThreadLocalMap 是一种使用线性探测法实现的哈希表
ThreadLocalMap 是一种使用线性探测法实现的哈希表,底层采用数组存储数据。如下图所示,ThreadLocalMap 会初始化一个长度为 16 的 Entry 数组,每个 Entry 对象用于保存 key-value 键值对。与 HashMap 不同的是,Entry 的 key 就是 ThreadLocal 对象本身,value 就是用户具体需要存储的值。
那么应该如何避免 ThreadLocalMap 内存泄漏呢?
ThreadLocal 已经帮助我们做了一定的保护措施,在执行 ThreadLocal.set()/get() 方法时,ThreadLocal 会清除 ThreadLocalMap 中 key 为 NULL 的 Entry 对象,让它还能够被 GC 回收。除此之外,当线程中某个 ThreadLocal 对象不再使用时,立即调用 remove() 方法删除 Entry 对象。如果是在异常的场景中,记得在 finally 代码块中进行清理,保持良好的编码意识。
FastThreadLocalThread 是对 Thread 类的一层包装,每个线程对应一个 InternalThreadLocalMap 实例。只有 FastThreadLocal 和 FastThreadLocalThread 组合使用时,才能发挥 FastThreadLocal 的性能优势。首先看下 FastThreadLocalThread 的源码定义:
上文中我们讲到了 ThreadLocal 的一个重要缺点,就是 ThreadLocalMap 采用线性探测法解决 Hash 冲突性能较慢,那么 InternalThreadLocalMap 又是如何优化的呢?
而是在 FastThreadLocal 初始化的时候分配一个数组索引 index,index 的值采用原子类 AtomicInteger 保证顺序递增,通过调用 InternalThreadLocalMap.nextVariableIndex() 方法获得。然后在读写数据的时候通过数组下标 index 直接定位到 FastThreadLocal 的位置,时间复杂度为 O(1)。如果数组下标递增到非常大,那么数组也会比较大,所以 FastThreadLocal 是通过空间换时间的思想提升读写性能。下面通过一幅图描述 InternalThreadLocalMap、index 和 FastThreadLocal 之间的关系。

本节课我们对比介绍了 ThreadLocal 和 FastThreadLocal,简单总结下 FastThreadLocal 的优势。
-
高效查找。FastThreadLocal 在定位数据的时候可以直接根据数组下标 index 获取,时间复杂度 O(1)。而 JDK 原生的 ThreadLocal 在数据较多时哈希表很容易发生 Hash 冲突,线性探测法在解决 Hash 冲突时需要不停地向下寻找,效率较低。此外,FastThreadLocal 相比 ThreadLocal 数据扩容更加简单高效,FastThreadLocal 只需要把数据容量扩容 2 倍,然后把原数据拷贝到新数组。而 ThreadLocal 由于采用的哈希表,所以在扩容后需要再做一轮 rehash。
-
安全性更高。JDK 原生的 ThreadLocal 使用不当可能造成内存泄漏,只能等待线程销毁。在使用线程池的场景下,ThreadLocal 只能通过主动检测的方式防止内存泄漏,从而造成了一定的开销。然而 FastThreadLocal 不仅提供了 remove() 主动清除对象的方法,而且在线程池场景中 Netty 还封装了 FastThreadLocalRunnable,FastThreadLocalRunnable 最后会执行 FastThreadLocal.removeAll() 将 Set 集合中所有 FastThreadLocal 对象都清理掉,
延迟任务处理神器之时间轮 HashedWheelTimer
####Timer 其实目前并不推荐用户使用,它是存在不少设计缺陷的。
Timer 是单线程模式。如果某个 TimerTask 执行时间很久,会影响其他任务的调度。
Timer 的任务调度是基于系统绝对时间的,如果系统时间不正确,可能会出现问题。
TimerTask 如果执行出现异常,Timer 并不会捕获,会导致线程终止,其他任务永远不会执行。
ScheduledThreadPoolExecutor 继承于 ThreadPoolExecutor,因此它具备线程池异步处理任务的能力。线程池主要负责管理创建和管理线程,并从自身的阻塞队列中不断获取任务执行。线程池有两个重要的角色,分别是任务和阻塞队列。
ScheduledThreadPoolExecutor 在 ThreadPoolExecutor 的基础上,重新设计了任务 ScheduledFutureTask 和阻塞队列 DelayedWorkQueue。ScheduledFutureTask 继承于 FutureTask,并重写了 run() 方法,使其具备周期执行任务的能力。DelayedWorkQueue 内部是优先级队列,deadline 最近的任务在队列头部。对于周期执行的任务,在执行完会重新设置时间,并再次放入队列中。
以上我们简单介绍了 JDK 三种实现定时器的方式。可以说它们的实现思路非常类似,都离不开任务、任务管理、任务调度三个角色。
时间轮原理分析
技术有时就源于生活,例如排队买票可以想到队列,公司的组织关系可以理解为树等,而时间轮算法的设计思想就来源于钟表。如下图所示,时间轮可以理解为一种环形结构,像钟表一样被分为多个 slot 槽位。每个 slot 代表一个时间段,每个 slot 中可以存放多个任务,使用的是链表结构保存该时间段到期的所有任务。时间轮通过一个时针随着时间一个个 slot 转动,并执行 slot 中的所有到期任务。

Netty HashedWheelTimer 源码解析
HashedWheelTimer 存在的问题
-
如果长时间没有到期任务,那么会存在时间轮空推进的现象。
-
只适用于处理耗时较短的任务,由于 Worker 是单线程的,如果一个任务执行的时间过长,会造成 Worker 线程阻塞。
-
相比传统定时器的实现方式,内存占用较大。
内部结构与上文中介绍的时间轮算法类似:

Kafka 也有时间轮的应用,它的实现思路与 Netty 是存在区别的,为了解决空推进的问题,Kafka 借助 JDK 的 DelayQueue 来负责推进时间轮。DelayQueue 保存了时间轮中的每个 Bucket,并且根据 Bucket 的到期时间进行排序,最近的到期时间被放在 DelayQueue 的队头,DelayQueue 插入和删除的性能并不好,其实 Kafka 采用的是一种权衡的策略,把 DelayQueue 用在了合适的地方。DelayQueue 只存放了 Bucket,Bucket 的数量并不多,相比空推进带来的影响是利大于弊的。
为了解决任务时间跨度很大的问题,Kafka 引入了层级时间轮,如下图所示。当任务的 deadline 超出当前所在层的时间轮表示范围时,就会尝试将任务添加到上一层时间轮中,跟钟表的时针、分针、秒针的转动规则是同一个道理。


从图中可以看出,第一层时间轮每个时间格为 1ms,整个时间轮的跨度为 20ms;第二层时间轮每个时间格为 20ms,整个时间轮跨度为 400ms;第三层时间轮每个时间格为 400ms,整个时间轮跨度为 8000ms。每一层时间轮都有自己的指针,每层时间轮走完一圈后,上层时间轮也会相应推进一格。
高性能无锁队列 Mpsc Queue
java并发队列

LinkedTransferQueue,一种特殊的无界阻塞队列,可以看作 LinkedBlockingQueues、SynchronousQueue(公平模式)、ConcurrentLinkedQueue 的合体。与 SynchronousQueue 不同的是,LinkedTransferQueue 内部可以存储实际的数据,当执行 put 操作时,如果有等待线程,那么直接将数据交给对方,否则放入队列中。与 LinkedBlockingQueues 相比,LinkedTransferQueue 使用 CAS 无锁操作进一步提升了性能。
ConcurrentLinkedDeque,也是一种采用双向链表结构的无界并发非阻塞队列。与 ConcurrentLinkedQueue 不同的是,ConcurrentLinkedDeque 属于双端队列,它同时支持 FIFO 和 FILO 两种模式,可以从队列的头部插入和删除数据,也可以从队列尾部插入和删除数据,适用于多生产者和多消费者的场景。
JCTools 也是一个开源项目,Github 地址为 https://github.com/JCTools/JCTools。JCTools 是适用于 JVM 并发开发的工具,主要提供了一些 JDK 确实的并发数据结构,例如非阻塞 Map、非阻塞 Queue 等。其中非阻塞队列可以分为四种类型,可以根据不同的场景选择使用。
Spsc 单生产者单消费者;
Mpsc 多生产者单消费者;
Spmc 单生产者多消费者;
Mpmc 多生产者多消费者。
Netty 中直接引入了 JCTools 的 Mpsc Queue,相比于 JDK 原生的并发队列,Mpsc Queue 又有什么过人之处呢?接下来便开始我们今天要讨论的重点。
Mpsc Queue 基础知识
Mpsc 的全称是 Multi Producer Single Consumer,多生产者单消费者。Mpsc Queue 可以保证多个生产者同时访问队列是线程安全的,而且同一时刻只允许一个消费者从队列中读取数据。Netty Reactor 线程中任务队列 taskQueue 必须满足多个生产者可以同时提交任务,所以 JCTools 提供的 Mpsc Queue 非常适合 Netty Reactor 线程模型

一般来说,CPU 会分为三级缓存,分别为L1 一级缓存、L2 二级缓存和L3 三级缓存。越靠近 CPU 的缓存,速度越快,但是缓存的容量也越小。所以从性能上来说,L1 > L2 > L3,容量方面 L1 < L2 < L3。CPU 读取数据时,首先会从 L1 查找,如果未命中则继续查找 L2,如果还未能命中则继续查找 L3,最后还没命中的话只能从内存中查找,读取完成后再将数据逐级放入缓存中。此外,多线程之间共享一份数据的时候,需要其中一个线程将数据写回主存,其他线程访问主存数据。
由此可见,引入多级缓存是为了能够让 CPU 利用率最大化。如果你在做频繁的 CPU 运算时,需要尽可能将数据保持在缓存中。那么 CPU 从内存中加载数据的时候,是如何提高缓存的利用率的呢?这就涉及缓存行(Cache Line)的概念,Cache Line 是 CPU 缓存可操作的最小单位,CPU 缓存由若干个 Cache Line 组成。Cache Line 的大小与 CPU 架构有关,在目前主流的 64 位架构下,Cache Line 的大小通常为 64 Byte。Java 中一个 long 类型是 8 Byte,所以一个 Cache Line 可以存储 8 个 long 类型变量。CPU 在加载内存数据时,会将相邻的数据一同读取到 Cache Line 中,因为相邻的数据未来被访问的可能性最大,这样就可以避免 CPU 频繁与内存进行交互了。
MpscArrayQueue 总结
通过大量填充 long 类型变量解决伪共享问题。
环形数组的容量设置为 2 的次幂,可以通过位运算快速定位到数组对应下标。
入队 offer() 操作中 producerLimit 的巧妙设计,大幅度减少了主动获取消费者索引 consumerIndex 的次数,性能提升显著。
入队和出队操作中都大量使用了 UNSAFE 系列方法,针对生产者和消费者的场景不同,使用的 UNSAFE 方法也是不一样的。Jctools 在底层操作的运用上也是有的放矢,把性能发挥到极致。
负载均衡策略
Round-Robin 轮询、Weighted Round-Robin 权重轮询、Least Connections 最少连接数、Consistent Hash 一致性 Hash 等
一致性Hash
在服务端节点扩缩容时,一致性 Hash 算法会尽可能保证客户端发起的 RPC 调用还是固定分配到相同的服务节点上。一致性 Hash 算法是采用哈希环来实现的,通过 Hash 函数将对象和服务器节点放置在哈希环上,一般来说服务器可以选择 IP + Port 进行 Hash,如下图所示。

一致性hash借助于TreeMap实现
public class ZKConsistentHashLoadBalancer implements ServiceLoadBalancer<ServiceInstance<ServiceMeta>> {
private final static int VIRTUAL_NODE_SIZE = 10;
private final static String VIRTUAL_NODE_SPLIT = "#";
@Override
public ServiceInstance<ServiceMeta> select(List<ServiceInstance<ServiceMeta>> servers, int hashCode) {
TreeMap<Integer, ServiceInstance<ServiceMeta>> ring = makeConsistentHashRing(servers); // 构造哈希环
return allocateNode(ring, hashCode); // 根据 hashCode 分配节点
}
private ServiceInstance<ServiceMeta> allocateNode(TreeMap<Integer, ServiceInstance<ServiceMeta>> ring, int hashCode) {
Map.Entry<Integer, ServiceInstance<ServiceMeta>> entry = ring.ceilingEntry(hashCode); // 顺时针找到第一个节点
if (entry == null) {
entry = ring.firstEntry(); // 如果没有大于 hashCode 的节点,直接取第一个
}
return entry.getValue();
}
private TreeMap<Integer, ServiceInstance<ServiceMeta>> makeConsistentHashRing(List<ServiceInstance<ServiceMeta>> servers) {
TreeMap<Integer, ServiceInstance<ServiceMeta>> ring = new TreeMap<>();
for (ServiceInstance<ServiceMeta> instance : servers) {
for (int i = 0; i < VIRTUAL_NODE_SIZE; i++) {
ring.put((buildServiceInstanceKey(instance) + VIRTUAL_NODE_SPLIT + i).hashCode(), instance);
}
}
return ring;
}
private String buildServiceInstanceKey(ServiceInstance<ServiceMeta> instance) {
ServiceMeta payload = instance.getPayload();
return String.join(":", payload.getServiceAddr(), String.valueOf(payload.getServicePort()));
}
}
Netty 高可用
共享 ChannelHandler
Netty 提供了 @Sharable 注解用于修饰 ChannelHandler,标识该 ChannelHandler 全局只有一个实例,而且会被多个 ChannelPipeline 共享。所以我们必须要注意的是,@Sharable 修饰的 ChannelHandler 必须都是无状态的,这样才能保证线程安全。
设置高低水位线
高低水位线 WRITE_BUFFER_HIGH_WATER_MARK 和 WRITE_BUFFER_LOW_WATER_MARK 是两个非常重要的流控参数。Netty 每次添加数据时都会累加数据的字节数,然后判断缓存大小是否超过所设置的高水位线,如果超过了高水位,那么 Channel 会被设置为不可写状态。直到缓存的数据大小低于低水位线以后,Channel 才恢复成可写状态。Netty 默认的高低水位线配置是 32K ~ 64K,可以根据发送端和接收端的实际情况合理设置高低水位线,如果你没有足够的测试数据作为参考依据,建议不要随意更改高低水位线。高低水位线的设置方式如下:
// Server
ServerBootstrap bootstrap = new ServerBootstrap();
bootstrap.childOption(ChannelOption.WRITE_BUFFER_HIGH_WATER_MARK, 32 * 1024);
bootstrap.childOption(ChannelOption.WRITE_BUFFER_LOW_WATER_MARK, 8 * 1024);
// Client
Bootstrap bootstrap = new Bootstrap();
bootstrap.option(ChannelOption.WRITE_BUFFER_HIGH_WATER_MARK, 32 * 1024);
bootstrap.option(ChannelOption.WRITE_BUFFER_LOW_WATER_MARK, 8 * 1024);
当缓存超过了高水位,Channel 会被设置为不可写状态,调用 isWritable() 方法会返回 false。建议在 Channel 写数据之前,使用 isWritable() 方法来判断缓存水位情况,防止因为接收方处理较慢造成 OOM。推荐的使用方式如下:
if (ctx.channel().isActive() && ctx.channel().isWritable()) {
ctx.writeAndFlush(message);
} else {
// handle message
}
GC 参数优化
-
堆内存:-Xms 和 -Xmx 参数,-Xmx 用于控制 JVM Heap 的最大值,必须设置其大小,合理调整 -Xmx 有助于降低 GC 开销,提升系统吞吐量。-Xms 表示 JVM Heap 的初始值,对于生产环境的服务端来说 -Xms 和 -Xmx 最好设置为相同值。
-
堆外内存:DirectByteBuffer 最容易造成 OOM 的情况,DirectByteBuffer 对象的回收需要依赖 Old GC 或者 Full GC 才能触发清理。如果长时间没有 Old GC 或者 Full GC 执行,那么堆外内存即使不再使用,也会一直在占用内存不释放。我们最好通过 JVM 参数 -XX:MaxDirectMemorySize 指定堆外内存的上限大小,当堆外内存的大小超过该阈值时,就会触发一次 Full GC 进行清理回收,如果在 Full GC 之后还是无法满足堆外内存的分配,那么程序将会抛出 OOM 异常。
-
年轻代:-Xmn 调整新生代大小,-XX:SurvivorRatio 设置 SurvivorRatio 和 eden 区比例。我们经常遇到 YGC 频繁的情况,应该清楚程序中对象的基本分布情况,如果存在大量朝生夕灭的对象,应适当调大新生代;反之应适当调大老年代。例如在类似百万长连接、推送服务等延迟敏感的场景中,老年代的内存增长缓慢,优化年轻代的空间大小以及各区的比例可以带来更大的收益。
内存池 & 对象池
为了减少堆外内存的频繁创建和销毁,Netty 提供了池化类型的 PooledDirectByteBuf。Netty 提前申请一块连续内存作为 ByteBuf 内存池,如果有堆外内存申请的需求直接从内存池里获取即可,使用完之后必须重新放回内存池,否则会造成严重的内存泄漏。Netty 中启用内存池可以在创建客户端或者服务端的时候指定,示例代码如下:
bootstrap.option(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT);
bootstrap.childOption(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT);
Netty 提供的 Recycler 对象池。Recycler 对象池如何使用在之前的课程有介绍过,在此我们一起回顾下。假设我们有一个 User 类,需要实现 User 对象的复用,具体实现代码如下:
public class UserCache {
private static final Recycler<User> userRecycler = new Recycler<User>() {
@Override
protected User newObject(Handle<User> handle) {
return new User(handle);
}
};
static final class User {
private String name;
private Recycler.Handle<User> handle;
public void setName(String name) {
this.name = name;
}
public String getName() {
return name;
}
public User(Recycler.Handle<User> handle) {
this.handle = handle;
}
public void recycle() {
handle.recycle(this);
}
}
public static void main(String[] args) {
User user1 = userRecycler.get(); // 1、从对象池获取 User 对象
user1.setName("hello"); // 2、设置 User 对象的属性
user1.recycle(); // 3、回收对象到对象池
User user2 = userRecycler.get(); // 4、从对象池获取对象
System.out.println(user2.getName());
System.out.println(user1 == user2);
}
}
Native 支持
从 4.0.16 版本起,Netty 提供了用 C++ 编写 JNI 调用的 Socket Transport,相比 JDK NIO 具备更高的性能和更低的 GC 成本,并且支持更多的 TCP 参数。
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-transport-native-epoll</artifactId>
<version>4.1.42.Final</version>
</dependency>
使用 Netty Native 非常简单,只需要替换相应的类即可:

线程绑定
目前 Java 中有一个开源 affinity 类库,GitHub 地址https://github.com/OpenHFT/Java-Thread-Affinity。如果你的项目想引入使用它,需要先引入 Maven 依赖:
<dependency>
<groupId>net.openhft</groupId>
<artifactId>affinity</artifactId>
<version>3.0.6</version>
</dependency>
affinity 类库可以和 Netty 轻松集成,比较常用的方式是创建一个 AffinityThreadFactory,然后传递给 EventLoopGroup,AffinityThreadFactory 负责创建 Worker 线程并完成绑核。代码实现如下所示:
EventLoopGroup bossGroup = new NioEventLoopGroup(1);
ThreadFactory threadFactory = new AffinityThreadFactory("worker", AffinityStrategies.DIFFERENT_CORE);
EventLoopGroup workerGroup = new NioEventLoopGroup(4, threadFactory);
ServerBootstrap serverBootstrap = new ServerBootstrap().group(bossGroup, workerGroup);
解码器保护
Netty 在实现数据解码时,需要等待到缓冲区有足够多的字节才能开始解码。为了避免缓冲区缓存太多数据造成内存耗尽,我们可以在解码器中设置一个最大字节的阈值,然后结合 Netty 提供的 TooLongFrameException 异常通知 ChannelPipeline 中其他 ChannelHandler。
线程池隔离
我们知道,如果有复杂且耗时的业务逻辑,推荐的做法是在 ChannelHandler 处理器中自定义新的业务线程池,将耗时的操作提交到业务线程池中执行。建议根据业务逻辑的核心等级拆分出多个业务线程池,如果某类业务逻辑出现异常造成线程池资源耗尽,也不会影响到其他业务逻辑,从而提高应用程序整体可用率。对于 Netty I/O 线程来说,每个 EventLoop 可以与某类业务线程池绑定,避免出现多线程锁竞争。
流量整形
流量整形(Traffic Shaping)是一种主动控制服务流量输出速率的措施,保证下游服务能够平稳处理。流量整形和流控的区别在于,流量整形不会丢弃和拒绝消息,无论流量洪峰有多大,它都会采用令牌桶算法控制流量以恒定的速率输出,如下图所示。
堆外内存泄漏排查思路
前面的课程我们介绍过堆外内存回收原理,建议你再回过头复习下。JDK 默认采用 Cleaner 回收释放 DirectByteBuffer,Cleaner 继承于 PhantomReference,因为依赖 GC 进行处理,所以回收的时间是不可控的。对于 hasCleaner 的 DirectByteBuffer,Java 提供了一系列不同类型的 MXBean 用于获取 JVM 进程线程、内存等监控指标,代码实现如下:
BufferPoolMXBean directBufferPoolMXBean = ManagementFactory.getPlatformMXBeans(BufferPoolMXBean.class).get(0);
LOGGER.info("DirectBuffer count: {}, MemoryUsed: {} K", directBufferPoolMXBean.getCount(), directBufferPoolMXBean.getMemoryUsed()/1024);
对于 Netty 中 noCleaner 的 DirectByteBuffer,直接通过 PlatformDependent.usedDirectMemory() 读取即可。
Netty 自带检测工具
Netty 提供了自带的内存泄漏检测工具,我们可以通过以下命令启用堆外内存泄漏检测工具:
-Dio.netty.leakDetection.level=paranoid
Netty 一共提供了四种检测级别:
-
disabled,关闭堆外内存泄漏检测;
-
simple,以 1% 的采样率进行堆外内存泄漏检测,消耗资源较少,属于默认的检测级别;
-
advanced,以 1% 的采样率进行堆外内存泄漏检测,并提供详细的内存泄漏报告;
-
paranoid,追踪全部堆外内存的使用情况,并提供详细的内存泄漏报告,属于最高的检测级别,性能开销较大,常用于本地调试排查问题。
Btrace 神器
Btrace 是一款通过字节码检测 Java 程序的排障神器,它可以获取程序在运行过程中的一切信息,与 AOP 的使用方式类似。我们可以通过如下方式追踪 DirectByteBuffer 的堆外内存申请的源头:
@BTrace
public class TraceDirectAlloc {
@OnMethod(clazz = "java.nio.Bits", method = "reserveMemory")
public static void printThreadStack() {
jstack();
}
}
二分排查法:笨方法解决大问题
堆外内存泄漏问题有时候非常隐蔽,并不是很容易定位发现。为了提高问题排查的效率,我们最好能够在本地模拟复现出堆外内存泄漏问题,如果本地能够成功复现,那么已经成功了一半了。
我们可以根据近期代码变更的记录,通过二分法对代码进行回滚,然后再次尝试是否可以复现出堆外内存泄漏问题,最终可以定位出有问题的代码 commit。该思路虽然是一种笨方法,但是很多场景下可以有效解决问题
Netty网络参数
如果你没有指定 workerGroup 线程组初始化的线程数,那么 Netty 会默认创建 2 倍 CPU 核数作的线程,但这并不一定是一个最佳数量,可以根据实际的压测情况进行适当调整。一般来说,只要服务性能能够满足要求,workerGroup 初始化的线程数应该越少越好,这样可以有效地减少线程上下文切换。
Netty 提供了一个参数 ioRatio,可以调整 I/O 事件处理和任务处理的时间比例,默认值为 50。对于高并发的 RPC 调用场景,ioRatio 可以适当调大,控制 Netty 有更多的时间比例在执行 I/O 任务。
Netty 提供了 ChannelOption 以便于我们优化 TCP 参数配置,为了提高网络通信的吞吐量,一些可选的网络参数我们有必要掌握。
-
TCP_NODELAY,是否开启 Nagle 算法。Nagle 算法通过缓存的方式将网络数据包累积到一定量才会发送,从而避免频繁发送小的数据包。Nagle 算法 在海量流量的场景下非常有效,但是会造成一定的数据延迟。如果对数据传输延迟敏感,那么应该禁用该参数。
-
SO_BACKLOG,已完成三次握手的请求队列最大长度。同一时刻服务端可能会处理多个连接,在高并发海量连接的场景下,该参数应适当调大。但是 SO_BACKLOG 也不能太大,否则无法防止 SYN-Flood 攻击。
-
SO_SNDBUF/SO_RCVBUF,TCP 发送缓冲区和接收缓冲区的大小。为了能够达到最大的网络吞吐量,SO_SNDBUF 不应当小于带宽和时延的乘积。SO_RCVBUF 一直会保存数据到应用进程读取为止,如果 SO_RCVBUF 满了,接收端会通知对端 TCP 协议中的窗口关闭,保证 SO_RCVBUF 不会溢出。
-
SO_KEEPALIVE,连接保活。启用了 TCP SO_KEEPALIVE 属性,TCP 会主动探测连接状态,Linux 默认设置了 2 小时的心跳频率。TCP KEEPALIVE 机制主要用于回收死亡时间交长的连接,不适合实时性高的场景。
连接空闲检测+心跳检测
连接空闲检测和心跳检测是应对连接假死的一种有效手段,通常空闲检测时间间隔要大于 2 个周期的心跳检测时间间隔,主要是为了排除网络抖动的造成心跳包未能成功收到。
Netty 中提供了开箱即用的 IdleStateHandler 实现连接空闲检测,如果我们想把一定时间间隔内没有读到数据的客户端连接进行关闭,可以采取如下的实现方式:
public class RpcIdleStateHandler extends IdleStateHandler {
public RpcIdleStateHandler() {
super(60, 0, 0, TimeUnit.SECONDS);
}
@Override
protected void channelIdle(ChannelHandlerContext ctx, IdleStateEvent evt) {
ctx.channel().close();
}
}
心跳检测在 Netty 中并没有现成的实现,但是与空闲检测实现的原理是差不多的,客户端可以采用 EventLoop 提供的 schedule() 方法向任务队列中添加心跳数据上报的定时任务,如下所示:
public class RpcHeartBeatHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
super.channelActive(ctx);
doHeartBeatTask(ctx);
}
private void doHeartBeatTask(ChannelHandlerContext ctx) {
ctx.executor().schedule(() -> {
if (ctx.channel().isActive()) {
HeartBeatData heartBeatData = buildHeartBeatData();
ctx.writeAndFlush(heartBeatData);
doHeartBeatTask(ctx);
}
}, 10, TimeUnit.SECONDS);
}
}
客户端向服务端定时发送心跳包,服务端收到后并不回复响应,因为如果同时与服务端建立的客户端连接规模较大,响应心跳数据需要消耗一定的资源。如果想要实现客户端和服务端互相感知存活状态,需要采用双向心跳机制。我们需要根据实际场景选择最合理的心跳检测方式。
线程池隔离
如果你的 RPC 服务是公司的基础服务,可能会有非常多的调用方,例如用户接口、订单接口等等。在我们实现的 RPC 框架中,业务线程池是共用的,所有的 RPC 请求都会有该线程池处理。如果有一天其中一个服务调用方的流量激增,导致线程池资源耗尽,那么其他服务调用方都会受到严重的影响。我们可以尝试将不同的服务调用方划分到不同等级的业务线程池中,通过分组的方式对服务调用方的流量进行隔离,从而避免其中一个调用方出现异常状态导致其他所有调用方都不可用,提高服务整体性能和可用率。
流量隔离技术是服务治理中非常重要的一个措施,在很多大规模流量的业务系统中都有所应用,例如秒杀系统,可以根据特殊的请求头识别出是否是秒杀请求,从而跟日常请求的流量隔离开来。那么对于 RPC 框架而言,如何对服务调用方进行合理的分组呢?一般来说,根据应用的重要等级作为分组依据是一个很好的衡量标准,一定要保障核心业务不受影响,例如下单、支付等接口都需要有自己独立的业务线程池,避免受到其他服务调用方的影响。
重试机制
重试机制你再熟悉不过了,在平时的项目开发中你一定经常用到。为了保障服务的稳定性和容错性,重试机制是一般可以帮助我们解决不少问题,例如网络抖动、请求超时等场景都需要重试机制。
集群容错
集群容错是指服务消费者调用服务提供者集群时发生异常时的处理方案。以 Dubbo 框架为例,提供了六种内置的集群容错措施。
Failover,失效转移策略。Failover 是 Dubbo 默认的集群容错措施,当出现调用失败时,会重新尝试调用其他服务节点。对于幂等性操作我们可以选择 Failover 策略,但是重试的副作用在上文中我们已经提到过,如果服务提供者出现问题可能会产生大量的重试请求。
Failfast,快速失败策略。Failfast 非常适合非幂等性操作,服务消费者只发起一次调用,如果出现失败的情况则立刻报错,不进行任何重试。Failfast 的缺点就是需要服务消费者自己控制重试逻辑。
Failsafe,失效安全策略。Failsafe 策略在出现异常时,直接忽略。Failsafe 策略适合执行非核心的操作,如监控日志记录。
Failback,失效自动恢复策略。服务消费者调用失败后,Dubbo 会记录此次失败请求到队列中,然后定时重新发送该请求。Failback 策略适用于实时性不高的场景,如消息推送。
Forking,并行措施。服务调用者并行调用多个服务提供者节点,只要有一个调用成功就返回结果。通常用于实时性要求较高的操作,而且可以降低 TP999 指标,但是需要牺牲一定的服务器资源。
Broadcast,广播措施。Broadcast 策略会广播所有的服务提供者,逐个调用,任意一台失败则等待广播最后完成之后抛出,通常用于更新服务提供方的本地资源状态。
以上几种集群容错措施可以根据实际的业务场景进行配置选择,而且 Dubbo 给我们提供了 Cluster 扩展接口,我们可以自己定制集群的容错模式。
此外,实现 RPC 框架高可用的措施还有很多,如限流保护、动态扩容、平滑重启、服务治理等等,由于篇幅有限,我在这里就不一一展开了。实现一个 RPC 框架原型并不是什么难事,但是如何保证 RPC 框架的高性能、高可用、易扩展,是需要我们不断去学习和积累的技能。
Netty 避免内存拷贝
CompositeByteBuf 是 Netty 中实现零拷贝机制非常重要的一个数据结构,它可以组合多个 Buffer 对象合并成一个逻辑上的对象,避免通过传统内存拷贝的方式将几个 Buffer 合并成一个大的 Buffer,我们经常使用 CompositeByteBuf 拼接协议数据的 头部信息 Header 和消息体数据 Body。
在失败重试的场景,我们想保留 ByteBuf 继续使用,你可以使用 copy() 方法拷贝原始 ByteBuf 的所有信息。但是深拷贝非常浪费性能的,你可以使用浅拷贝操作 oldBuffer.duplicate().retain() 复制出独立的读写索引,底层分配的内存、引用计数都是与原始 ByteBuf 共享的,其中 retain() 又会将 ByteBuffer 的引用计数加 1,从而避免了 ByteBuffer 被释放。